Overview of our work.
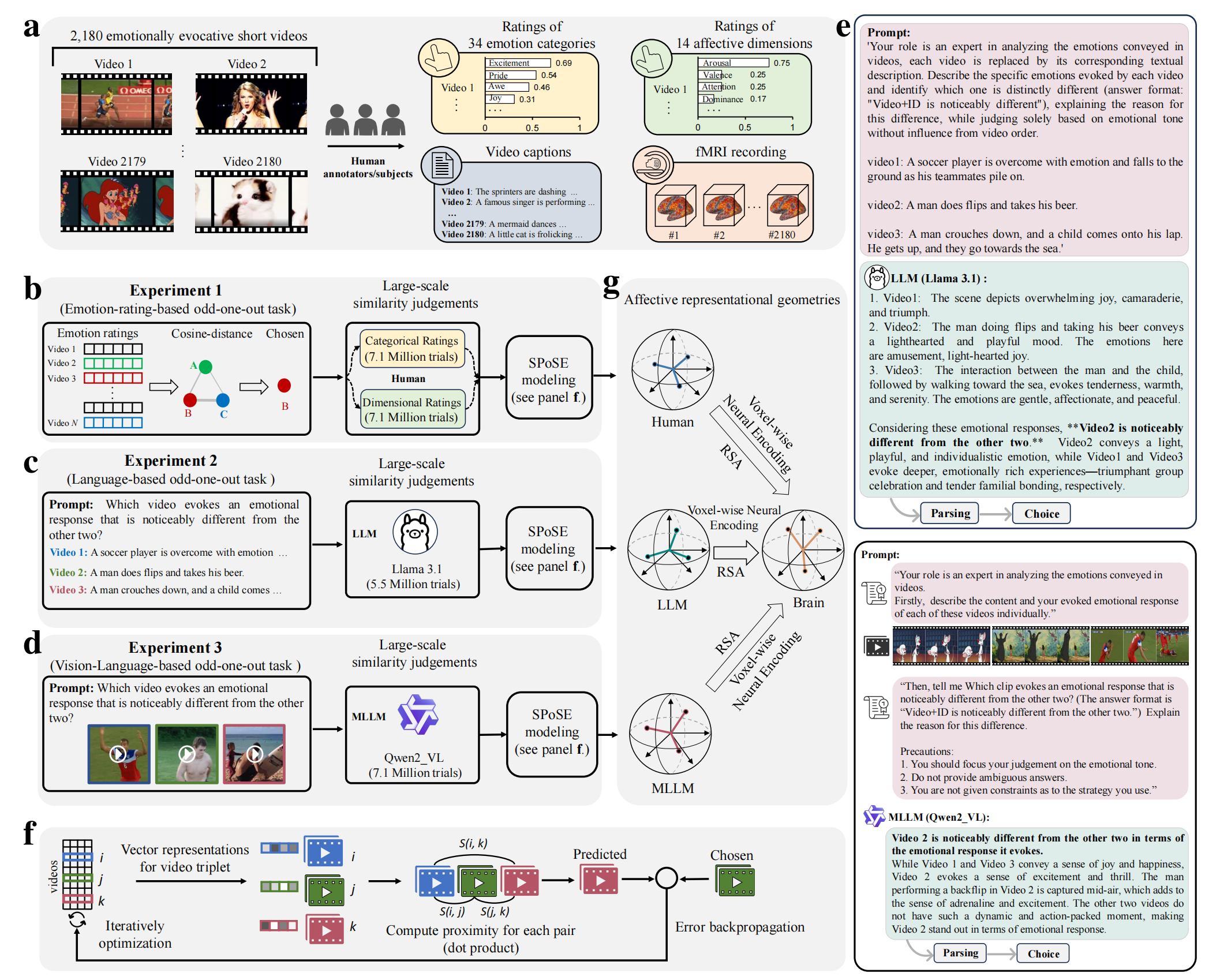
Overview of the experimental and analytical pipeline.
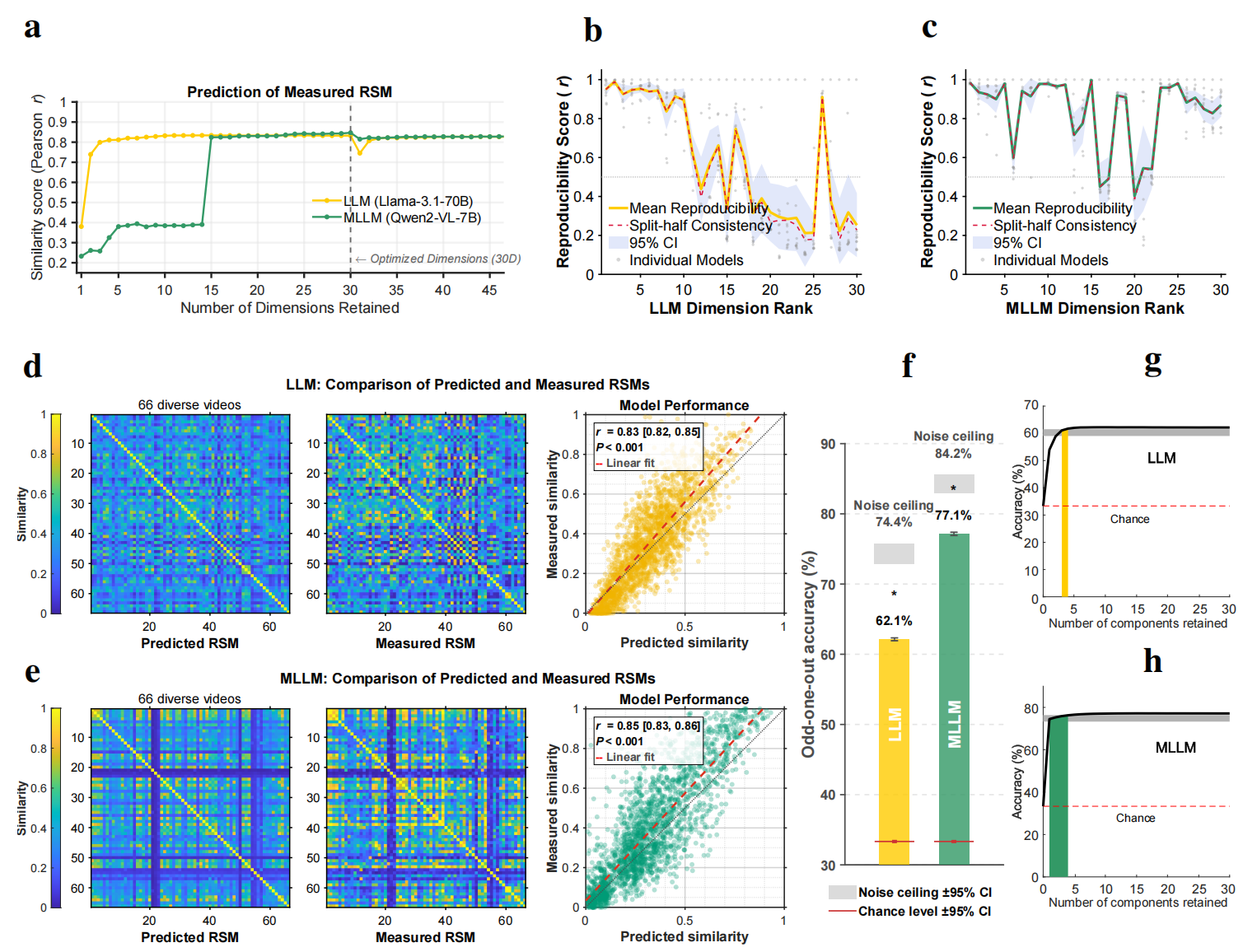
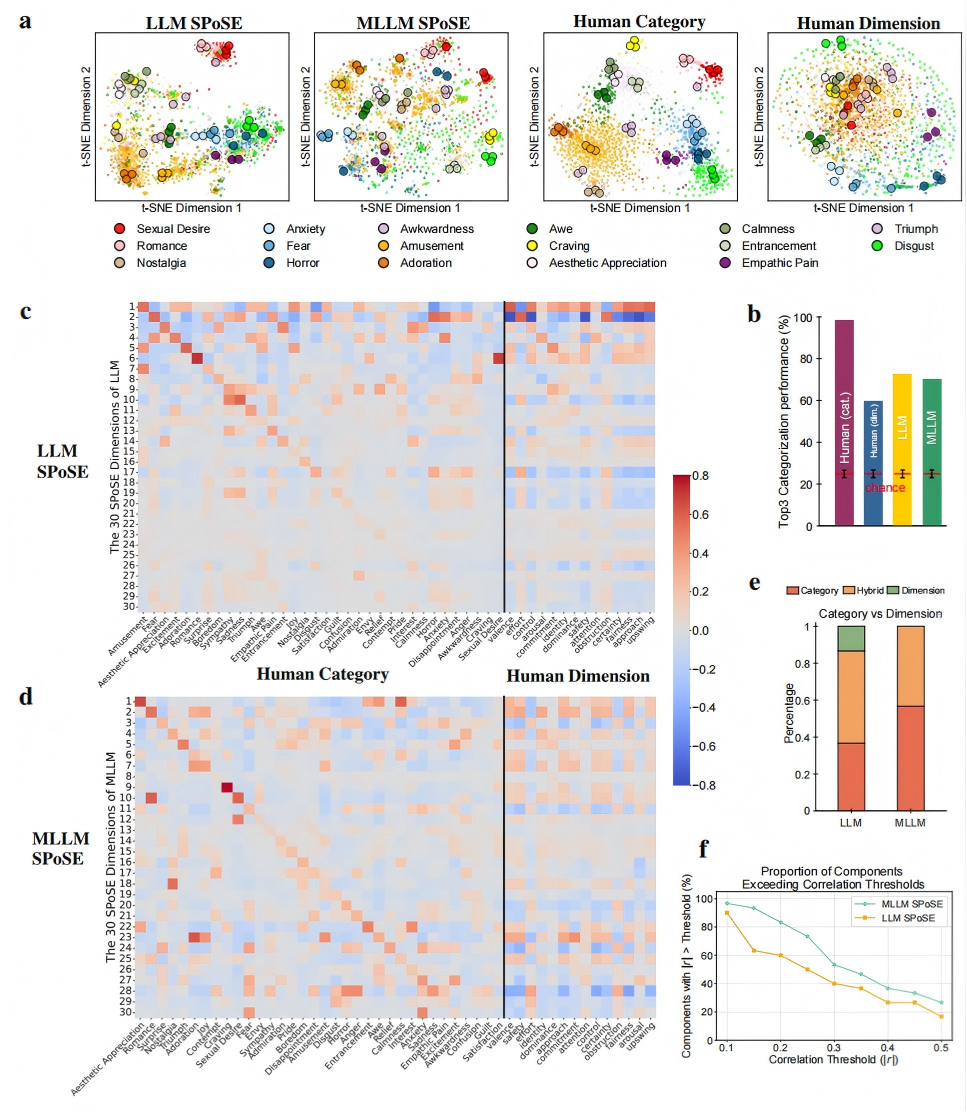
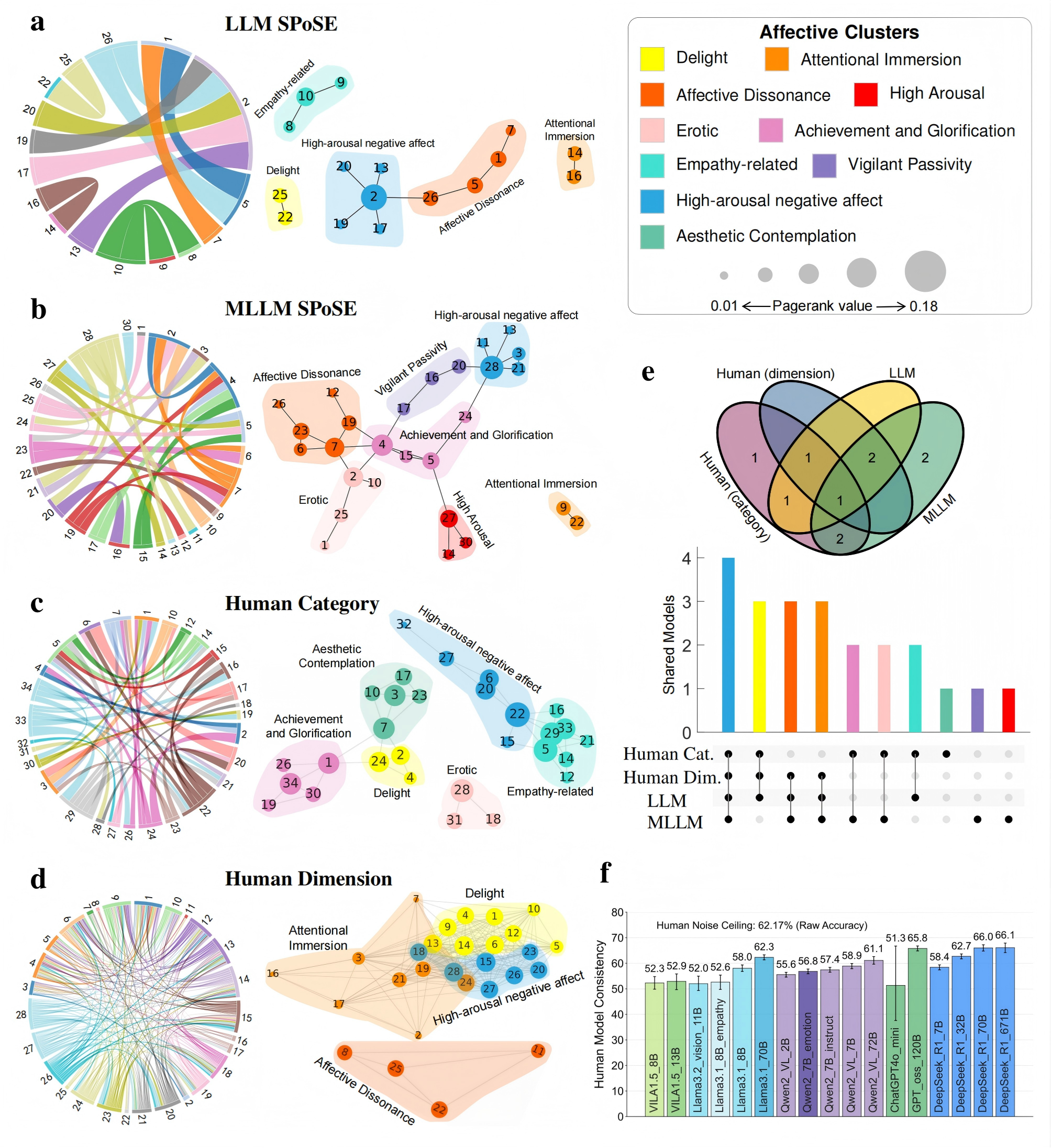
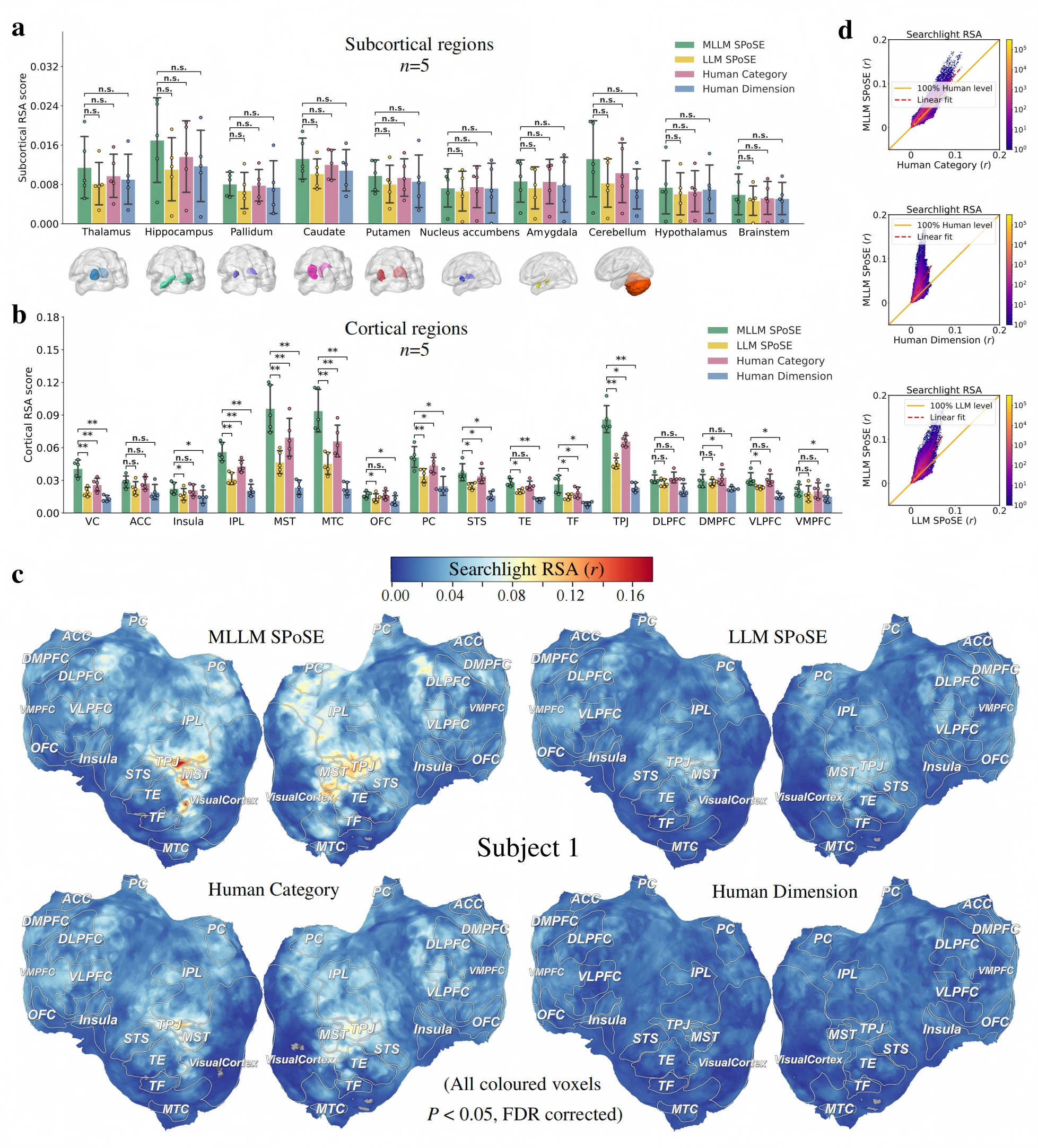
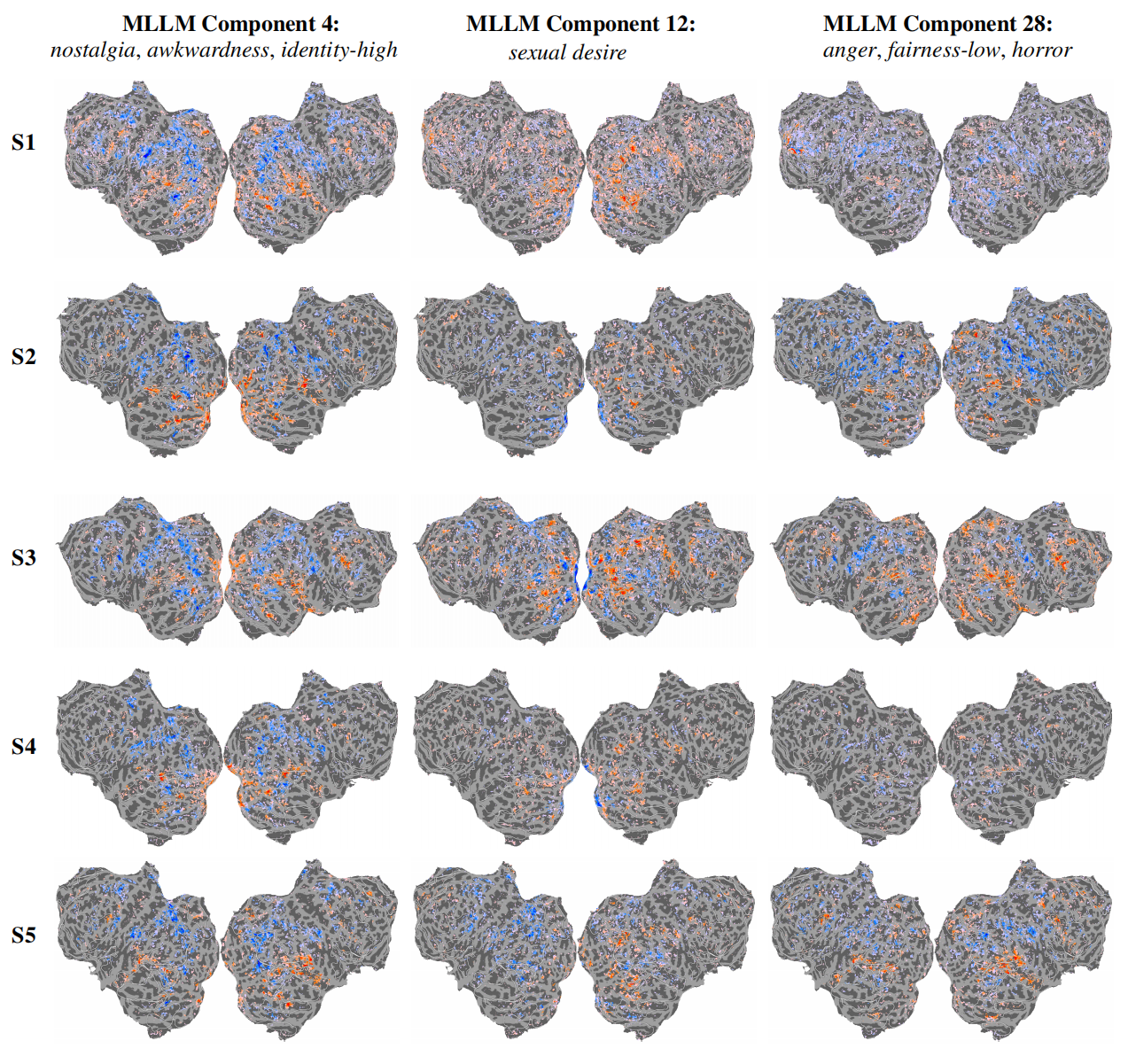
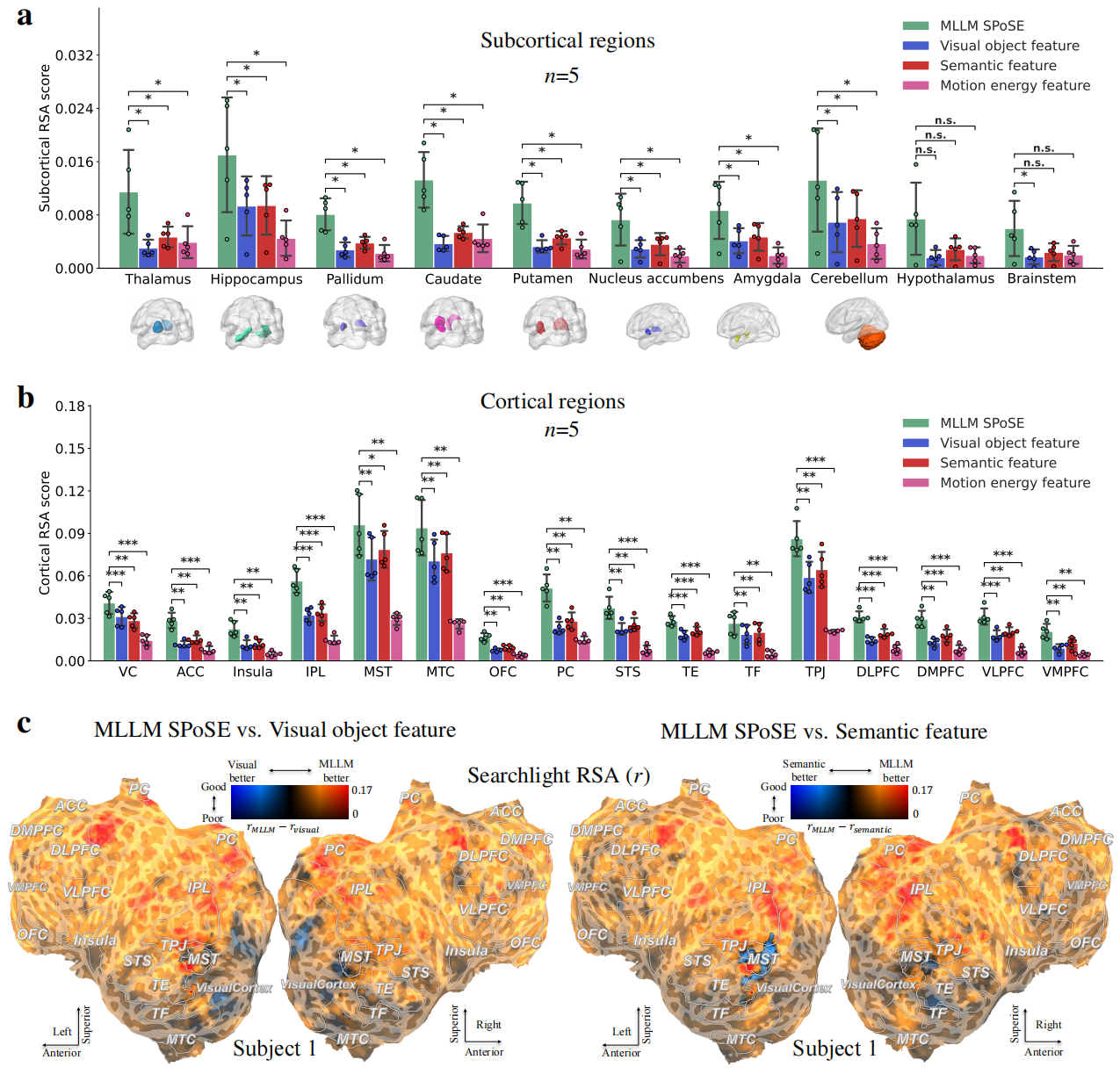
a, The study utilized a database of 2,180 emotionally evocative videos with rich, pre-existing annotations, including human ratings on discrete emotion categories and continuous affective dimensions, detailed textual descriptions, and corresponding fMRI data from human viewers. b-d, MLLM (b) and LLM (c) use a triplet odd-one-out behavioral paradigm to collect millions of triplet judgments, and the latent embeddings of videos were learned from these judgments by using SPoSE (d). e, Example prompts and responses for the LLM and MLLM. f, Testing the behavioral consistency between human and various AI models (across architectures, scales, and modalities) on a newly collected dataset of 30,000 triplet judgments from human participants (n=100). g, Comparing the model-derived representations against traditional human rating models in predicting brain activity.